隨著大數(shù)據(jù)技術(shù)的迅猛發(fā)展,Hadoop已不再是唯一的選擇。雖然Hadoop為分布式數(shù)據(jù)處理奠定了基礎(chǔ),但如今市場(chǎng)涌現(xiàn)出許多更高效、更靈活的技術(shù)。以下是除Hadoop外,你應(yīng)該關(guān)注的9個(gè)大數(shù)據(jù)技術(shù),這些技術(shù)覆蓋數(shù)據(jù)處理、存儲(chǔ)、分析和實(shí)時(shí)計(jì)算等關(guān)鍵領(lǐng)域。
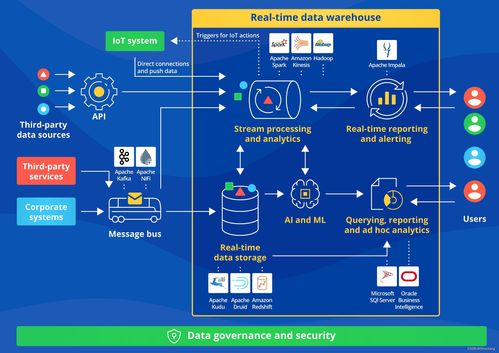
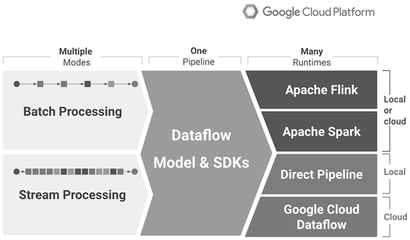
- Spark:作為一個(gè)快速、通用的集群計(jì)算系統(tǒng),Spark在內(nèi)存計(jì)算方面表現(xiàn)出色,支持批處理、流處理和機(jī)器學(xué)習(xí)。相比Hadoop的MapReduce,Spark的速度更快,特別適合迭代算法和實(shí)時(shí)分析。
- Kafka:由Apache開發(fā)的一個(gè)分布式流處理平臺(tái),Kafka用于構(gòu)建實(shí)時(shí)數(shù)據(jù)管道和流應(yīng)用。它能夠高效處理高吞吐量的數(shù)據(jù)流,廣泛應(yīng)用于日志聚合、事件源和消息隊(duì)列場(chǎng)景。
- Flink:一個(gè)開源的流處理框架,F(xiàn)link支持事件驅(qū)動(dòng)型應(yīng)用,并提供精確一次的處理語義。它在實(shí)時(shí)數(shù)據(jù)處理和復(fù)雜事件處理方面具有優(yōu)勢(shì),適合需要低延遲和高可靠性的應(yīng)用。
- Cassandra:一個(gè)高度可擴(kuò)展的NoSQL數(shù)據(jù)庫,Cassandra設(shè)計(jì)用于處理大量數(shù)據(jù)跨多個(gè)數(shù)據(jù)中心分布。它提供高可用性和無單點(diǎn)故障,適合寫入密集型應(yīng)用。
- Elasticsearch:一個(gè)分布式搜索和分析引擎,基于Lucene構(gòu)建。Elasticsearch能夠快速索引和查詢大規(guī)模數(shù)據(jù),常用于日志分析、全文搜索和實(shí)時(shí)監(jiān)控。
- Presto:由Facebook開發(fā)的分布式SQL查詢引擎,Presto允許在多種數(shù)據(jù)源(如HDFS、Cassandra和MySQL)上執(zhí)行快速查詢。它無需將數(shù)據(jù)移動(dòng)到單獨(dú)系統(tǒng)中,提升了分析效率。
- Snowflake:一個(gè)云原生數(shù)據(jù)倉庫,Snowflake提供彈性的存儲(chǔ)和計(jì)算分離架構(gòu)。它支持多租戶和自動(dòng)擴(kuò)展,簡化了大數(shù)據(jù)管理,適合企業(yè)級(jí)數(shù)據(jù)分析和報(bào)告。
- Airflow:一個(gè)用于編排復(fù)雜工作流的平臺(tái),Airflow允許用戶以代碼方式定義、調(diào)度和監(jiān)控?cái)?shù)據(jù)處理任務(wù)。它支持依賴管理和錯(cuò)誤處理,是數(shù)據(jù)工程中常用的工具。
- TensorFlow:雖然主要被視為機(jī)器學(xué)習(xí)框架,但TensorFlow在大數(shù)據(jù)處理中用于構(gòu)建和部署AI模型。它支持分布式訓(xùn)練,能夠處理海量數(shù)據(jù),推動(dòng)數(shù)據(jù)驅(qū)動(dòng)的智能應(yīng)用。
這些技術(shù)各具特色,能夠滿足不同場(chǎng)景下的需求。在選擇時(shí),需根據(jù)項(xiàng)目的數(shù)據(jù)量、實(shí)時(shí)性要求和資源約束進(jìn)行評(píng)估。大數(shù)據(jù)生態(tài)系統(tǒng)持續(xù)演進(jìn),掌握這些工具將幫助你在數(shù)據(jù)處理服務(wù)中保持競(jìng)爭(zhēng)力。